¿Ethernet, Infiniband u otra cosa?
Las Demandas sin Precedentes de la Era de la IA
La explosión de la inteligencia artificial no es solo una revolución del software; es un evento sísmico para la infraestructura subyacente que la soporta. Los modelos de IA, que crecen en complejidad a un ritmo de 1,000 veces cada tres años, están imponiendo una tensión brutal en los centros de datos, especialmente en la red, el sistema nervioso que conecta miles de procesadores de alto costo. La vieja máxima de que «la red es el ordenador» nunca ha sido más cierta. Sin embargo, las redes tradicionales, diseñadas para el tráfico de internet asíncrono y en ráfagas, simplemente no están equipadas para las demandas únicas y sostenidas de las cargas de trabajo de la IA. Esta brecha ha desencadenado una carrera frenética entre los gigantes tecnológicos para rediseñar la red desde cero, forjando una nueva generación de «Fabrics de IA» capaces de alimentar a las bestias computacionales que definen nuestra era.
Por Qué las Redes Tradicionales se Doblegan Bajo el Peso de la IA
Las cargas de trabajo de la inteligencia artificial, en particular el entrenamiento de modelos de lenguaje grandes (LLM), no solo requieren más ancho de banda. Exigen un nivel de rendimiento de red que es fundamentalmente diferente y mucho más estricto que el de las aplicaciones de centros de datos tradicionales. El fracaso en cumplir con estos requisitos no solo ralentiza el rendimiento; socava la viabilidad económica de las operaciones de IA a gran escala.

El Triunvirato del Rendimiento: Sin Pérdidas, Determinista y de Baja Fluctuación
El mantra para las redes de IA va más allá de la velocidad bruta. El rendimiento se define por un triplete de características no negociables: debe ser determinista, sin pérdidas y con una fluctuación (jitter) extremadamente baja. En los clústeres de GPU distribuidos, donde miles de procesadores trabajan en paralelo en un solo problema computacional, incluso una pérdida de paquetes aparentemente menor o una variación en la latencia puede tener efectos en cascada. Estas interrupciones pueden corromper la integridad de los datos que se mueven entre los nodos, lo que a su vez puede degradar la precisión del modelo que se está entrenando y, en última instancia, paralizar el rendimiento de todo el clúster. Una red que pierde un solo paquete en el momento equivocado puede obligar a costosos ciclos de retransmisión, dejando a miles de procesadores inactivos.
La Tiranía del Tiempo de Finalización del Trabajo (JCT)
En el mundo de la IA, la métrica de rendimiento más importante no es el ancho de banda por sí sola, ni siquiera la latencia promedio. Es el Tiempo de Finalización del Trabajo (Job Completion Time – JCT). Este es el tiempo total que se tarda en entrenar un modelo, desde el inicio hasta la finalización. La razón de su importancia es puramente económica. Los servidores de IA, equipados con múltiples Unidades de Procesamiento Gráfico (GPU) de alto rendimiento, son activos de capital extraordinariamente caros. Un solo servidor de entrenamiento con ocho GPUs puede costar más de 350.000 Euros, y las GPUs representan hasta el 80% de los costos totales de entrenamiento de IA. Un clúster a gran escala representa una inversión de cientos de millones de Euros.
Cada segundo que estas costosas GPUs permanecen inactivas, esperando datos de la red, es una pérdida financiera directa y catastrófica. La investigación de Meta reveló un dato alarmante: en promedio, un 33% del tiempo transcurrido en las cargas de trabajo de IA se gasta simplemente esperando a la red. Esto transforma a la red de un centro de costos de infraestructura a un habilitador crítico del rendimiento y el retorno de la inversión (ROI) de los activos más valiosos del centro de datos. La motivación principal detrás de la inversión multimillonaria en I+D en redes de IA no es simplemente hacer las redes más rápidas, sino maximizar la utilización y la eficiencia de las inversiones en GPU, que son aún más caras.
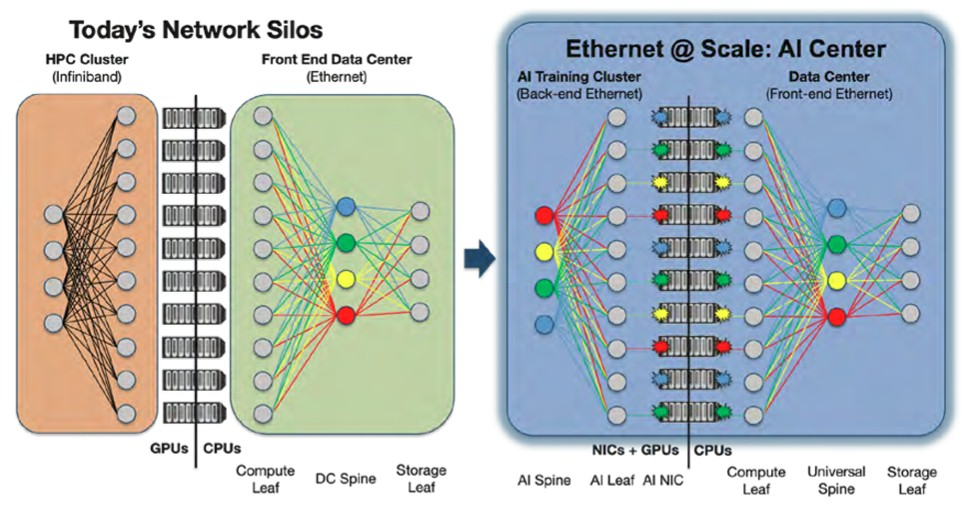
Flujos Elefante y la Superautopista Este-Oeste
A diferencia del tráfico tradicional de internet, que fluye predominantemente de «norte a sur» (de los usuarios a los servidores y viceversa), el entrenamiento de IA genera un patrón de tráfico completamente diferente. Se caracteriza por «flujos elefante»: flujos de datos masivos y sostenidos que se mueven de «este a oeste» a través del centro de datos, entre las miles de GPUs que colaboran en una tarea. Estos flujos no son ráfagas esporádicas; son torrentes de datos constantes que deben mantenerse durante todo el ciclo de entrenamiento. La red que los soporta, a menudo denominada «red de back-end», debe estar diseñada para manejar un volumen de tráfico hasta cinco veces mayor que la red de front-end y soportar miles de trabajos paralelos y sincronizados sin interrupción.
El Problema del «Camino Más Lento» y la Latencia de Cola
En un sistema de computación distribuida como un clúster de IA, el progreso de todos los nodos puede ser frenado por el flujo más lento. Esto significa que el rendimiento general del sistema no está determinado por la latencia promedio, sino por la latencia del peor caso, también conocida como latencia de cola (tail latency). La latencia de cola se refiere a los retrasos experimentados por la porción más lenta de las transferencias de datos, típicamente los percentiles 95 a 99 de los tiempos de entrega de paquetes.
Incluso si el 99% de los paquetes llegan a tiempo, ese 1% rezagado puede detener todo el proceso de entrenamiento, ya que muchos algoritmos requieren que todos los datos de una iteración lleguen antes de que pueda comenzar la siguiente. Este pequeño retraso se agrava con el tiempo, aumentando drásticamente el JCT, dejando las GPUs inactivas y limitando la escalabilidad del clúster. Por lo tanto, minimizar la latencia de cola, no solo la latencia promedio, es un objetivo de diseño primordial para los fabrics de IA.
El Efecto del Jitter
El jitter, o la variación en la latencia, es particularmente perjudicial para las cargas de trabajo de IA distribuidas, especialmente aquellas que se extienden a través de entornos de borde o multinube. Los protocolos de red tradicionales como el TCP interpretan consistentemente el jitter como una señal de congestión de la red. En respuesta, los algoritmos de control de congestión de TCP reducirán drásticamente el rendimiento para evitar la pérdida de datos, incluso si hay un amplio ancho de banda disponible. Esto puede llevar a un colapso del rendimiento de la red, deteniendo las cargas de trabajo de IA y dejando las GPUs inactivas. Este problema se ve agravado por la naturaleza impredecible de los flujos de datos de IA, la sobrecarga de la virtualización y los desafíos de sincronización en entornos distribuidos.
La Anatomía de una Red de Centro de Datos de IA
Para satisfacer estas demandas extremas, la arquitectura de red dentro de un centro de datos de IA ha evolucionado hacia un diseño de dos niveles altamente especializado. Esta bifurcación refleja los requisitos fundamentalmente diferentes del tráfico que entra y sale del clúster frente al tráfico que circula dentro de él.
Fabrics de Front-End vs. Back-End
El discurso sobre las redes de IA a menudo se simplifica en exceso. En realidad, los centros de datos modernos están construyendo dos redes distintas con requisitos, costos y tecnologías fundamentalmente diferentes.
- Red de Front-End: Esta red maneja el tráfico «norte-sur». Sus funciones principales son la ingesta de los enormes conjuntos de datos necesarios para el entrenamiento y la gestión de las solicitudes de los usuarios externos para la inferencia (cuando el modelo entrenado se utiliza para hacer predicciones). Aunque debe ser de alta velocidad, sus características de tráfico son más parecidas a las de una red de centro de datos tradicional a hiperescala. Se espera que los puertos Ethernet sigan siendo la norma aquí, hay predicciones ya pronosticando que un tercio de todos los puertos de la red de front-end alcanzarán velocidades de 800 Gbps o superiores para 2027.
- Red de Back-End: Aquí es donde se libra la verdadera batalla por el rendimiento. Esta es el fabric de interconexión especializada y construida a medida para el tráfico «este-oeste» entre las GPUs, las TPUs y otros aceleradores de IA (XPUs). Esta red debe manejar un volumen de tráfico significativamente mayor y está sujeta a requisitos de latencia y sin pérdidas mucho más estrictos. La migración a velocidades más altas es mucho más agresiva en el back-end, y se proyecta que casi todos los puertos alcancen los 800 Gbps y más para 2027, con una tasa de crecimiento anual compuesta (CAGR) de tres dígitos para el crecimiento del ancho de banda. Es en esta red de back-end donde compiten tecnologías como InfiniBand y Ethernet de alto rendimiento.
Esta bifurcación arquitectónica tiene profundas implicaciones estratégicas. Un proveedor como Cisco, tradicionalmente dominante en el mercado empresarial y de front-end, debe desarrollar soluciones de back-end altamente especializadas (como su Chip G200) para seguir siendo relevante en la era de la IA. Por el contrario, un líder en el back-end como NVIDIA con InfiniBand está impulsando agresivamente sus plataformas Ethernet (como Spectrum-X) para capturar también el mercado de front-end. El mercado no es un único campo de batalla, sino dos interconectados, lo que obliga a los proveedores a adoptar una estrategia de doble vertiente y a los operadores a integrar y gestionar dos dominios de red distintos dentro del mismo clúster de IA.

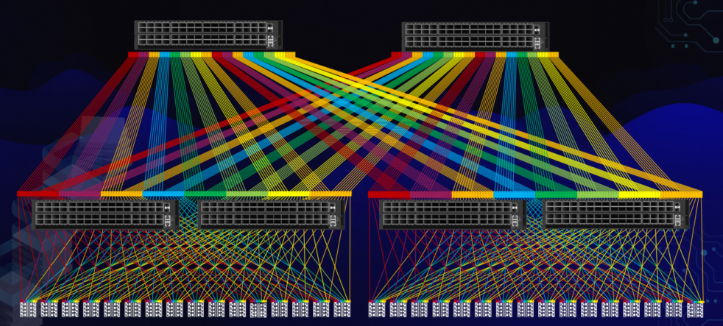
El Ascenso de la Topología de Clos
Para construir estas redes de back-end masivas y sin bloqueo, la industria ha estandarizado en gran medida la topología de red de múltiples etapas (leaf-and-spine), también conocida como topología de Clos. Esta arquitectura proporciona múltiples rutas entre dos puntos finales cualesquiera, lo que permite un alto rendimiento y resistencia. En un diseño de dos niveles, los servidores (hojas) se conectan a un conjunto de conmutadores (leaf switches), y cada conmutador leaf se conecta a cada conmutador de Spine (spine switch). Este diseño garantiza que cualquier servidor esté a un número predecible y bajo de saltos de cualquier otro servidor, lo cual es crucial para mantener una latencia baja y determinista.
Patrones de Comunicación Colectiva
El corazón del tráfico de entrenamiento de IA se define por operaciones de comunicación colectiva, donde grupos de procesadores deben intercambiar datos de manera sincronizada. La red debe estar optimizada para manejar estos patrones de manera eficiente.
- All-to-All: Este es uno de los patrones de comunicación más exigentes. En una operación All-to-All, cada procesador (GPU) en un grupo envía un mensaje individual a todos los demás procesadores del grupo. Esto crea una explosión de tráfico simultáneo que puede saturar rápidamente una red no preparada. Es común en el entrenamiento de modelos grandes, como los modelos de transformadores, y pone a prueba la capacidad del fabric para manejar una congestión masiva sin pérdida de paquetes ni aumento de la latencia.
- All-Reduce: Este patrón es fundamental para la sincronización de los gradientes en el entrenamiento de datos en paralelo. En una operación All-Reduce, los datos de todos los nodos (por ejemplo, los gradientes calculados localmente) se agregan, se realiza una operación de reducción (como una suma), y el resultado final se distribuye de nuevo a todos los nodos.16 Este proceso requiere una combinación de alto ancho de banda para mover los datos y una latencia muy baja para garantizar que la fase de sincronización sea lo más corta posible, minimizando el tiempo de inactividad de la GPU.
Técnicas de Paralelismo
La red de back-end debe soportar de manera flexible diversas estrategias de computación paralela utilizadas para entrenar modelos masivos que no caben en una sola GPU. Estas incluyen el paralelismo de datos (dividir los datos de entrenamiento entre las GPUs), el paralelismo de tubería (dividir las capas del modelo entre las GPUs) y el paralelismo de tensor (dividir las operaciones de matriz individuales entre las GPUs). Cada una de estas técnicas impone patrones de comunicación únicos y exigentes en la red subyacente.
La Gran Guerra de los Fabric: El Ascenso de Ethernet
En el corazón de la carrera por construir la red de IA definitiva se encuentra un conflicto tecnológico fundamental: la batalla entre InfiniBand, el campeón propietario y de alto rendimiento, y Ethernet, el retador ubicuo y de estándar abierto. Esta no es simplemente una comparación técnica de protocolos; es una guerra estratégica por el futuro del centro de datos, con implicaciones económicas y operativas masivas.
InfiniBand – El Campeón Reinante de HPC
Durante más de dos décadas, InfiniBand ha sido la interconexión de elección para la computación de alto rendimiento (HPC) y los clústeres de supercomputación. Su arquitectura fue diseñada desde el principio para las cargas de trabajo más exigentes del mundo, lo que la convirtió en la opción natural para los primeros clústeres de IA a gran escala.
El Estándar de Oro
La reputación de InfiniBand se basa en su rendimiento superior, que se deriva de varias ventajas arquitectónicas clave.
- Diseño Nativo sin Pérdidas: A diferencia de Ethernet, que fue diseñado como una red de «mejor esfuerzo» y requiere complementos para evitar la pérdida de paquetes, InfiniBand es inherentemente sin pérdidas. Utiliza un mecanismo de control de flujo a nivel de enlace basado en créditos para garantizar que un nodo emisor nunca envíe datos a menos que el receptor tenga espacio en el búfer para recibirlos. Este diseño de «cero pérdida de paquetes» elimina la necesidad de retransmisiones, que son una fuente importante de latencia e ineficiencia en las redes tradicionales.
- Latencia Ultra Baja: InfiniBand logra una latencia extremadamente baja al eludir la pila de red del sistema operativo. A través del Acceso Directo a Memoria Remota (RDMA) nativo, permite que los datos se transfieran directamente de la memoria de un servidor a la memoria de otro sin la intervención de la CPU. Esto reduce drásticamente la sobrecarga de procesamiento y permite latencias de extremo a extremo tan bajas como 90 nanosegundos con la plataforma Quantum-2 de NVIDIA, o consistentemente por debajo de los 2 microsegundos, significativamente más bajas que las soluciones Ethernet tradicionales.
- Computación en Red (In-Network Computing): Quizás el diferenciador más poderoso de InfiniBand es su capacidad para realizar operaciones de computación directamente dentro de la red. Tecnologías como el Protocolo de Agregación y Reducción Jerárquica Escalable (SHARP) de NVIDIA permiten que las operaciones colectivas, como All-Reduce, se descarguen de las GPUs a los conmutadores de la red. Al realizar la agregación de datos mientras están en tránsito, SHARP reduce drásticamente la cantidad de datos que necesitan atravesar la red, liberando a las GPUs para que se centren en la computación y acelerando significativamente el tiempo de finalización del trabajo.
- La Fortaleza de NVIDIA: Tras la adquisición de Mellanox, el ecosistema de InfiniBand está predominantemente controlado por NVIDIA. Esto ha creado una solución de IA de extremo a extremo fuertemente integrada y de alto rendimiento, que abarca desde la GPU hasta la tarjeta de red (HCA) y el conmutador. Sin embargo, esta integración tiene un costo: una solución propietaria con un fuerte bloqueo de proveedor (vendor lock-in).
Ethernet Re-Pensado: El Ascenso de RoCEv2 y el Centro de Datos sin Pérdidas
Durante años, Ethernet fue considerado inadecuado para las cargas de trabajo de HPC y IA debido a su naturaleza intrínsecamente con pérdidas y su mayor latencia. Sin embargo, una ola de innovación, impulsada por un amplio consorcio de la industria, ha transformado a Ethernet de un protocolo de «mejor esfuerzo» a un fabric de alto rendimiento capaz de desafiar el dominio de InfiniBand.
La Transformación de Ethernet
La pieza central de la reinvención de Ethernet es el RDMA sobre Ethernet Convergente (RoCEv2). Este protocolo lleva los beneficios de RDMA, como la omisión del kernel y la baja latencia, a las redes Ethernet estándar. A diferencia de su predecesor (RoCEv1), RoCEv2 encapsula el transporte RDMA sobre UDP/IP, lo que lo hace enrutable a través de redes de Capa 3. Esto permite que los clústeres de IA se escalen a través de grandes centros de datos sin las limitaciones de un único dominio de Capa 2.
El Conjunto de Herramientas sin Pérdidas
Lograr un Fabric sin pérdidas con Ethernet no es una característica inherente; requiere la implementación y el ajuste cuidadoso de un conjunto específico de tecnologías estándar que trabajan en conjunto para imitar el comportamiento sin pérdidas de InfiniBand.
- Control de Flujo por Prioridad (PFC / IEEE 802.1Qbb): Esta es la base de una red RoCEv2 sin pérdidas. PFC es un mecanismo a nivel de enlace que permite pausar selectivamente el tráfico para prioridades específicas (clases de tráfico) sin detener todo el tráfico en el enlace. Cuando el búfer de un conmutador para el tráfico RoCEv2 comienza a llenarse, envía una trama de pausa PFC al dispositivo emisor, diciéndole que detenga temporalmente el envío de ese tipo de tráfico, evitando así el desbordamiento del búfer y la pérdida de paquetes.
- Notificación Explícita de Congestión (ECN): Mientras que PFC previene la pérdida de paquetes debido a la congestión del búfer de entrada (microbursts), ECN es un mecanismo de gestión de congestión de extremo a extremo. Cuando un conmutador detecta que un puerto de salida se está congestionando, marca un campo en la cabecera IP de los paquetes que pasan. El nodo receptor ve esta marca y envía un paquete de notificación de congestión (CNP) de vuelta al emisor original, indicándole que reduzca su velocidad de envío. Esto alivia la congestión antes de que se produzca la pérdida de paquetes.
- Notificación de Congestión Cuantificada del Centro de Datos (DCQCN): Este es un algoritmo de control de congestión mejorado, diseñado específicamente para redes RoCEv2. Combina las señales de ECN y PFC para proporcionar un control de velocidad más granular y estable, creando un Fabric Ethernet sin pérdidas que está específicamente diseñada para las demandas de las cargas de trabajo de IA.
Con estas tecnologías, el Ethernet optimizado para IA puede cerrar significativamente la brecha de rendimiento con InfiniBand. Las latencias pueden reducirse a niveles de microsegundos bajos de un solo dígito, acercándose al rendimiento de InfiniBand. De hecho, en algunos benchmarks de entrenamiento de MLPerf a gran escala, se ha demostrado que las soluciones Ethernet igualan o incluso superan ligeramente el rendimiento de InfiniBand, lo que demuestra su viabilidad como una alternativa de alto rendimiento.
Una Batalla de Economía y Ecosistemas
Si bien la brecha de rendimiento técnico entre InfiniBand y Ethernet se ha reducido drásticamente, la batalla por el dominio de las redes de IA se libra cada vez más en los frentes de la economía, la apertura y la simplicidad operativa. Aquí es donde Ethernet tiene una ventaja decisiva. La victoria de Ethernet no está garantizada solo por la tecnología, sino por su ecosistema abierto y su economía superior. Aunque InfiniBand todavía mantiene una ventaja en la latencia bruta, el rendimiento «suficientemente bueno» de RoCEv2, combinado con un ahorro masivo en el costo total de propiedad y la simplicidad operativa, lo está convirtiendo en la opción predeterminada para los hiperescaladores y un número creciente de empresas. La guerra se está ganando en las hojas de cálculo y en los departamentos de recursos humanos, no solo en los nanosegundos.
El Costo Total de Oportunidad (TCO)
El TCO es la carta de triunfo de Ethernet. El análisis de los costos revela una disparidad significativa.
- Gastos de Capital (CapEx): InfiniBand es un ecosistema en gran medida de un solo proveedor, lo que resulta en costos más altos para el hardware especializado y propietario, como conmutadores, adaptadores de canal de host (HCAs) y cables.Por el contrario, Ethernet se beneficia de un ecosistema masivo, competitivo y de múltiples proveedores que reduce los precios del hardware a través de las economías de escala. Varios análisis de la industria demuestran esta ventaja. Un estudio encontró que una solución Ethernet de Juniper ofrece un TCO un 55% más bajo en comparación con una solución InfiniBand de NVIDIA.Otro análisis de costos para la construcción de clústeres de IA mostró que las soluciones basadas en RoCE podrían lograr tasas de ahorro de costos de entre el 49% y el 70% en comparación con InfiniBand, dependiendo de la escala y la arquitectura específicas.
- Gastos Operativos (OpEx): La ventaja de Ethernet se extiende a los costos operativos. El grupo de talentos de ingenieros de redes con experiencia en la configuración, gestión y solución de problemas de redes Ethernet es vasto y está fácilmente disponible. InfiniBand, por otro lado, es una habilidad de nicho. La operación de un Fabric de InfiniBand requiere personal especializado y capacitación, lo que aumenta la complejidad operativa y los costos continuos.
El Cambio del Mercado
Estos factores económicos están impulsando un cambio tangible en el mercado. Los datos ilustran esta tendencia. Mientras que InfiniBand dominaba el mercado de redes de back-end de IA en 2023 con más del 80% de la cuota de mercado, Ethernet está ganando terreno rápidamente. El grupo de analistas predice que Ethernet está ahora firmemente posicionado para superar a InfiniBand en implementaciones de alto rendimiento a medida que la industria se mueve a velocidades de 800 Gbps y más allá. Se espera que la cuota de ingresos de los conmutadores Ethernet gane 20 puntos para 2027, lo que indica un cambio significativo en las preferencias de los clientes.
Flexibilidad e Interoperabilidad
La ventaja fundamental de Ethernet es su naturaleza abierta y basada en estándares. Esto permite a las organizaciones realizar actualizaciones incrementales, mantener la compatibilidad con versiones anteriores e integrar sin problemas nuevos componentes de diferentes proveedores. Un fabric Ethernet puede abarcar todo el centro de datos, desde el borde hasta el núcleo y la nube, sin necesidad de pasarelas propietarias para traducir entre diferentes tecnologías de red. Esta flexibilidad y la ausencia de bloqueo de proveedor son inmensamente atractivas para los hiperescaladores y las grandes empresas que buscan construir infraestructuras de IA escalables y preparadas para el futuro.
La elección entre InfiniBand y Ethernet es la decisión estratégica central para cualquier organización que construya un clúster de IA. Esta decisión no es puramente técnica; es profundamente económica y operativa. La siguiente tabla resume las complejas compensaciones multifacéticas, proporcionando un marco de toma de decisiones crucial.
| Característica | InfiniBand | Ethernet Optimizado para IA (RoCEv2) |
| Protocolo Central | Propietario, optimizado para HPC | Estándar abierto (IEEE 802.3), ubicuo |
| Perfil de Latencia | Ultra bajo (sub-microsegundo, tan bajo como 90ns) | Bajo (microsegundos de un solo dígito bajo) |
| Mecanismo sin Pérdidas | Nativo (control de flujo basado en créditos) | Añadido (requiere PFC, ECN, DCQCN) |
| Diferenciador Clave | Computación en Red (ej. NVIDIA SHARP) | Ecosistema abierto, interoperabilidad, TCO |
| Costo de Hardware (CapEx) | Alto (hardware especializado y propietario) | Menor (mercado competitivo de múltiples proveedores) |
| Ecosistema de Proveedores | Dominado por NVIDIA (bloqueo de proveedor) | Vasto y diverso (Broadcom, Cisco, Arista, Intel, etc.) |
| Experiencia Operativa (OpEx) | Habilidad de nicho, personal especializado requerido | Ampliamente disponible, conjunto de habilidades estándar de la industria |
| Modelo de Escalabilidad | Escalabilidad de alto rendimiento dentro de su ecosistema | Escalabilidad flexible en todo el centro de datos y la nube |
| Fortaleza Clave | Rendimiento bruto máximo y latencia más baja | Costo total de propiedad, flexibilidad, apertura |
| Debilidad Clave | Costo, bloqueo de proveedor, complejidad operativa | Requiere una configuración y ajuste cuidadosos para un rendimiento sin pérdidas |
La Carrera Armamentista del Silicio: Forjando el Futuro de las Redes de IA
La guerra de los fabrics entre Ethernet e InfiniBand se libra en última instancia a nivel de silicio. En el corazón de cada conmutador de red se encuentra un Circuito Integrado de Aplicación Específica (ASIC) altamente complejo, y es aquí donde los principales fabricantes están invirtiendo miles de millones en investigación y desarrollo para obtener una ventaja competitiva. La batalla por la supremacía en las redes de IA es una carrera armamentista de silicio, con cada proveedor adoptando estrategias y filosofías de diseño distintas para resolver los desafíos únicos que plantean las cargas de trabajo de IA.
El Club de los 51.2 Tbps – El Nuevo Estándar para Conmutadores de IA
El punto de referencia actual para un conmutador de red de IA de gama alta es una capacidad de conmutación de 51.2 terabits por segundo (Tbps). Esta enorme capacidad, típicamente entregada a través de 64 puertos de 800 gigabits por segundo (Gbps), se ha convertido en la base para construir los fabrics de IA a gran escala de la próxima generación. Los principales proveedores de silicio han lanzado sus ASICs insignia de 51.2T, cada uno con un enfoque único para optimizar el rendimiento de la IA.
Broadcom (Tomahawk 5 & Tomahawk Ultra)
Broadcom, un proveedor dominante de silicio de conmutación mercantil, ha adoptado un enfoque de doble vertiente.
- Tomahawk 5 (BCM78900): Este es el caballo de batalla para los fabric de IA a escala. Es un ASIC monolítico de 5nm que ofrece 51.2 Tbps de ancho de banda (64x800G). Su característica de IA más destacada es el
Enrutamiento Cognitivo (Cognitive Routing). A diferencia del hash estático tradicional, que puede crear puntos calientes en la red, el Enrutamiento Cognitivo selecciona de forma dinámica y automática los enlaces menos congestionados del sistema para cada flujo. Combinado con el equilibrio de carga dinámico en tiempo real, esto mejora drásticamente la utilización de la red, reduce la congestión y, lo más importante, acorta el JCT. También cuenta con una arquitectura avanzada de búfer compartido diseñada para minimizar la latencia de cola para el tráfico RoCEv2. - Tomahawk Ultra: Anunciado en julio de 2025, el Tomahawk Ultra no es una actualización incremental, sino una reimaginación revolucionaria del conmutador Ethernet, diseñado específicamente para los clústeres de HPC y de escalado vertical de IA.Rompe las barreras de latencia de Ethernet, logrando una asombrosa
latencia de conmutación de 250 nanosegundos, una mejora drástica con respecto a los 600-1000ns típicos de los conmutadores para la nube. Introduce dos capacidades que cambian el juego:
Colectivos en Red (In-Network Collectives), que descargan operaciones como All-Reduce directamente en el conmutador para liberar las GPUs, y un fabric verdaderamente sin pérdidas que utiliza la Repetición a Nivel de Enlace (Link Layer Retry – LLR) y el Control de Flujo Basado en Créditos (Credit-Based Flow Control – CBFC) para eliminar la pérdida de paquetes a nivel de hardware.
Cisco (Silicon One G200)
El G200 de Cisco es un dispositivo de 5nm y 51.2 Tbps con 512 SerDes de 112 Gbps. El diferenciador clave de Cisco es su enfoque en un radix extremadamente alto, ofreciendo 512 puertos de 100GE en un solo chip. Esta estrategia de diseño tiene profundas implicaciones para la arquitectura de la red. Permite la construcción de topologías de red más planas. Por ejemplo, un clúster de 32,000 GPUs se puede construir con una red de solo 2 capas utilizando el G200, lo que requiere un 50% menos de ópticas y un 40% menos de conmutadores en comparación con las alternativas de menor radix. Esta reducción drástica en el número de componentes no solo reduce los costos de capital y el consumo de energía, sino que también disminuye la latencia general al minimizar el número de saltos que un paquete debe atravesar. El G200 también cuenta con técnicas avanzadas de equilibrio de carga consciente de la congestión y de pulverización de paquetes (packet-spraying) para evitar la formación de puntos calientes.
Marvell (Teralynx 10)
El Teralynx 10 de Marvell es otro conmutador monolítico de 5nm y 51.2 Tbps. La propuesta de valor única de Marvell es la combinación de una latencia ultra baja (que afirman ser la más baja de cualquier conmutador programable) con un pipeline de reenvío totalmente programable sin impacto en el rendimiento. Esta programabilidad es una ventaja estratégica significativa, ya que permite a los operadores de red adaptar el comportamiento del conmutador a nuevos protocolos (como el emergente UET del Ultra Ethernet Consortium) o a requisitos de carga de trabajo específicos mediante una actualización de software, en lugar de un costoso ciclo de actualización de hardware. El Teralynx 10 también integra capacidades avanzadas de telemetría con su tecnología Teralynx Flashlight™ para una visibilidad profunda de la red.
La siguiente tabla ofrece una comparación directa de estos ASICs de conmutación de IA de 51.2T, destacando sus diferentes enfoques de ingeniería para resolver el mismo problema central.
| ASIC | Fabricante | Ancho de Banda / Puertos | Nodo de Proceso | Característica Arquitectónica Clave | Característica(s) de IA Diferenciadora(s) | Perfil de Latencia |
| Tomahawk 5 | Broadcom | 51.2 Tbps / 64x800G | 5nm | Monolítico, Búfer Compartido | Enrutamiento Cognitivo, Equilibrio de Carga Dinámico 4 | Bajo (optimizado para RoCEv2) |
| Tomahawk Ultra | Broadcom | 51.2 Tbps / 64x800G | 5nm | Monolítico, Optimizado para HPC | Colectivos en Red, Fabic sin Pérdidas (LLR, CBFC) | Ultra Bajo (250ns) |
| Silicon One G200 | Cisco | 51.2 Tbps / 512x100G | 5nm | Radix más Alto de la Industria | Topologías de Red Más Planas, Reducción de Componentes | Bajo (2x menor que la gen. anterior) |
| Teralynx 10 | Marvell | 51.2 Tbps / 64x800G | 5nm | Pipeline de Reenvío Programable | Programabilidad sin Impacto en el Rendimiento, a Prueba de Futuro 56 | Ultra Bajo (el más bajo para un conmutador programable) 56 |
Fabrics Especializadas y Estrategias Diferenciadas
Más allá del club de los 51.2T, varios proveedores están persiguiendo estrategias especializadas, centrándose en diferentes aspectos del problema de la red de IA, desde la construcción de Fabrics masivas y perfectamente programadas hasta la adición de valor a través de software inteligente.
El Fabric Programado de Broadcom (Jericho3-AI)
El ASIC Jericho3-AI (BCM88890) de Broadcom representa un enfoque diferente. En lugar de la máxima velocidad en un solo chip, está diseñado para construir Fabric de Ethernet masivas y perfectamente programadas. Con una capacidad de 28.8 Tbps, puede interconectar hasta 32,000 GPUs en un solo clúster. Sus características distintivas son el equilibrio de carga perfecto, que pulveriza el tráfico de manera uniforme en todos los enlaces disponibles para una máxima utilización, y la operación libre de congestión a través de la programación de tráfico de extremo a extremo. Este enfoque de «Ethernet programado» tiene como objetivo eliminar las colisiones de flujos y el jitter, y Broadcom afirma que puede acortar el JCT en al menos un 10% para cargas de trabajo exigentes como All-to-All en comparación con las soluciones de red alternativas.
El Enfoque Definido por Software de Arista
La estrategia de Arista Networks no es fabricar su propio chip de silicio, sino aprovechar los mejores ASICs de mercado (como el Tomahawk y el Jericho de Broadcom) y crear un valor diferenciado a través de su software avanzado y su diseño de sistema holístico.
- Hardware: La base de hardware de Arista para IA consiste en sus conmutadores leaf fijos de la serie 7060X y sus conmutadores de spine modulares de la serie 7800R. La serie 7800R es particularmente notable por su arquitectura de búfer profundo y Cola de Salida Virtual (Virtual Output Queue – VOQ), que elimina el bloqueo de cabeza de línea (Head-of-Line blocking) y previene la pérdida de paquetes incluso en escenarios de red muy congestionados.
- Software (EOS & CloudVision): El verdadero diferenciador de Arista es su pila de software. Su sistema operativo de red, Arista EOS, proporciona implementaciones robustas de RoCEv2, PFC/ECN y una característica avanzada llamada Equilibrio de Carga de Clúster (Cluster Load Balancing – CLB).A diferencia del equilibrio de carga tradicional, CLB adopta una visión global del fabric para optimizar simultáneamente los flujos tanto de leaf a spine como de spine a leaf, maximizando la eficiencia de la red. Su plataforma de gestión, CloudVision, proporciona automatización centralizada y observabilidad centrada en la IA, lo que permite a los operadores correlacionar eventos de la red (como pausas de PFC) con métricas de rendimiento de la aplicación como el JCT.
La Visión Programable de Intel (Tofino)
La serie de ASICs Tofino de Intel ocupa una posición única en el mercado debido a su programabilidad en P4. A diferencia de los conmutadores de función fija, Tofino permite a los operadores de red definir sus propios pipelines de procesamiento de paquetes en software. Esto ofrece una flexibilidad sin precedentes para experimentar con nuevos protocolos, implementar telemetría personalizada o crear lógica de reenvío a medida para cargas de trabajo de IA específicas.La reciente decisión de Intel de abrir el código del software Tofino P4 democratiza aún más esta capacidad, permitiendo a una comunidad más amplia innovar en el plano de datos de la red.
La Estrategia de Dominio de Extremo a Extremo de NVIDIA
NVIDIA ocupa una posición única y formidable en el ecosistema de la IA. Como la única empresa que proporciona la pila completa, desde la GPU hasta la interconexión de la GPU (NVLink), el Fabric y la pila de software (CUDA), NVIDIA puede ofrecer una solución de IA de extremo a extremo fuertemente integrada y optimizada. Su estrategia de red es doble, defendiendo su fortaleza de InfiniBand mientras lanza una ofensiva en el creciente mercado de Ethernet.
La Fortaleza de InfiniBand (Quantum-2)
Para los clientes que priorizan el rendimiento bruto por encima de todo, la plataforma InfiniBand Quantum-2 de NVIDIA sigue siendo la solución de mayor rendimiento.
- Hardware: En el corazón de la plataforma se encuentran los conmutadores QM9700 y QM9790, basados en el ASIC Quantum-2. Este ASIC ofrece una capacidad de 51.2 Tbps, proporcionando 64 puertos de InfiniBand NDR de 400 Gb/s.
- Computación en Red: La joya de la corona de la plataforma es su avanzada capacidad de Computación en Red. La tercera generación de la tecnología SHARP de NVIDIA (SHARPv3) permite que los conmutadores de la red participen activamente en las operaciones de comunicación colectiva, descargando estas tareas de las GPUs. NVIDIA afirma que SHARPv3 ofrece una potencia de aceleración de IA 32 veces mayor que la generación anterior. La plataforma también cuenta con capacidades de red de autorreparación y control de congestión avanzado para maximizar el rendimiento de las aplicaciones.
La Ofensiva de Ethernet (Spectrum-X)
Reconociendo el imparable impulso de Ethernet, NVIDIA ha desarrollado Spectrum-X, su respuesta para proporcionar un fabric Ethernet de alto rendimiento y optimizada para IA que aprovecha la experiencia de extremo a extremo de la compañía.
- Plataforma Fuertemente Acoplada: Spectrum-X no es solo un conmutador; es una plataforma que integra estrechamente el conmutador Ethernet Spectrum-4 (un ASIC de 51.2T) con el SuperNIC BlueField-3. Un SuperNIC es una nueva clase de acelerador de red diseñado para sobrealimentar las cargas de trabajo de IA a hiperescala.
- RoCE Optimizado para IA: La sinergia entre el conmutador y el SuperNIC permite a NVIDIA mejorar el estándar RoCE con características de valor añadido como el enrutamiento adaptativo y el aislamiento del rendimiento. Esto crea un rendimiento más predecible y consistente, especialmente en entornos de nube de IA multi-inquilino. NVIDIA afirma que la plataforma Spectrum-X ofrece una mejora de 1.7 veces en el rendimiento de la IA y la eficiencia energética en comparación con las soluciones Ethernet estándar.
Sección 9: El Ascenso de la DPU: Descargando la Infraestructura
A medida que las redes se vuelven más rápidas, la carga de gestionar las tareas de infraestructura (red, seguridad y almacenamiento) en la CPU del host se convierte en un cuello de botella significativo. La Unidad de Procesamiento de Datos (DPU), también conocida como SmartNIC, ha surgido como una solución crítica. La DPU es un procesador especializado que descarga estas tareas de infraestructura de la CPU, liberándola para que se dedique por completo a la computación de aplicaciones.
AMD (Pensando Systems)
Las DPUs Pensando de AMD (incluyendo las generaciones Giglio, Elba y la nueva Salina) se centran en acelerar los servicios de red de front-end para los clústeres de IA. Son totalmente programables en P4 y destacan en la descarga de redes definidas por software (SDN) multi-inquilino, aceleración de la seguridad y virtualización del almacenamiento. La adopción por parte de los principales proveedores de la nube, como Microsoft Azure, que informó de una mejora de 40 veces en el rendimiento relacionado con las conexiones, valida su eficacia. La nueva DPU Salina promete duplicar el rendimiento y la escala de la generación anterior, consolidando la posición de AMD en este espacio.
NVIDIA (BlueField-3)
La DPU BlueField-3 de NVIDIA es un pilar de su estrategia de computación acelerada. Comercializada como una «infraestructura en un chip», la BlueField-3 integra hasta 16 núcleos Arm y una serie de aceleradores de hardware dedicados para la red, el almacenamiento y la seguridad. Dentro de la plataforma Spectrum-X, la BlueField-3 funciona como un SuperNIC, proporcionando la inteligencia en el punto final necesaria para habilitar las características avanzadas de RoCE optimizado para IA, como el enrutamiento adaptativo y el aislamiento del rendimiento.
Marvell (OCTEON 10)
La familia de DPUs OCTEON 10 de Marvell está construida sobre un proceso de 5nm y utiliza núcleos Arm Neoverse N2. Su principal diferenciador es la inclusión de innovadores aceleradores de hardware para la inferencia de ML/IA en línea, que según Marvell ofrecen una ganancia de rendimiento de 100 veces sobre el procesamiento basado en software. La OCTEON 10 también integra un conmutador de 1 Terabit y motores de criptografía en línea, lo que la convierte en una potente solución para una amplia gama de aplicaciones de borde y de centro de datos.
La evolución de la industria revela un cambio de paradigma fundamental. La red está pasando de ser un simple conducto pasivo a convertirse en un fabric de computación programable y activa. Los proveedores más avanzados están integrando capacidades computacionales directamente en el tejido de la red. Esto se manifiesta en características como los Colectivos en Red de Broadcom en el Tomahawk Ultra y la tecnología SHARP de NVIDIA en Quantum-2. Este enfoque transforma la red de una tubería «tonta» a un participante activo en el proceso de computación. Al descargar tareas como las operaciones colectivas de las GPUs, la red libera a estos costosos procesadores para que se centren en su tarea principal: la computación matemática. Esto reduce aún más el JCT y representa un cambio fundamental en la arquitectura de los sistemas de IA. El futuro de las redes de IA no se trata solo del transporte de datos, sino de la computación en red. La red misma se está convirtiendo en un coprocesador distribuido, una tendencia que solo se acelerará.
El Camino a Seguir: Estándares Abiertos, Nuevos Paradigmas y Límites Físicos
A medida que la carrera armamentista del silicio se intensifica, la industria de las redes de IA se enfrenta a un nuevo conjunto de desafíos y oportunidades. El futuro estará determinado por tres fuerzas clave: el impulso hacia estándares abiertos para garantizar la interoperabilidad y evitar el bloqueo de proveedores, la búsqueda incesante del próximo salto en el rendimiento y las duras realidades físicas y económicas que limitan la escalabilidad de la IA.
El Consorcio Ultra Ethernet (UEC) – Un Frente Unido
La formación del Ultra Ethernet Consortium (UEC) en 2023 marca un punto de inflexión en la evolución de las redes de IA. Representa un esfuerzo concertado de toda la industria para crear una alternativa abierta, interoperable y de alto rendimiento al ecosistema propietario de InfiniBand.Aunque se posiciona públicamente como un organismo de estándares técnicos, el propósito estratégico principal del UEC es nivelar el campo de juego y evitar el dominio de un solo proveedor en la infraestructura crítica de la IA. Sus miembros fundadores incluyen a casi todos los principales actores del ecosistema de Ethernet: AMD, Arista, Broadcom, Cisco, Intel, Meta y Microsoft.
La Especificación UEC 1.0
En junio de 2025, el UEC lanzó la versión 1.0 de su especificación, que detalla una nueva pila de comunicaciones completa diseñada para las cargas de trabajo de IA y HPC. La especificación introduce varias innovaciones clave:
- Transporte Ultra Ethernet (UET): El corazón de la especificación es el UET, un nuevo protocolo de transporte diseñado para reemplazar a RoCEv2. A diferencia del TCP, que es un protocolo de flujo de bytes, el UET es un protocolo orientado a paquetes encapsulado en UDP para una fácil interoperabilidad con las redes existentes. Introduce múltiples modos de entrega de paquetes, incluyendo la Entrega Fiable no Ordenada (Reliable Unordered Delivery – RUD). El modo RUD es particularmente importante porque permite que los paquetes lleguen fuera de orden, reduciendo la latencia de cabeza de línea para las aplicaciones que no requieren un ordenamiento estricto de paquetes.
- Gestión Avanzada de la Congestión: El UET incorpora un control de congestión de grano fino, pulverización de paquetes en múltiples rutas y un ordenamiento flexible para lograr una mayor utilización de la red y una menor latencia de cola, abordando directamente los cuellos de botella del rendimiento en los clústeres de IA a gran escala.
- Repetición a Nivel de Enlace (LLR): En un cambio significativo con respecto a los protocolos tradicionales, la especificación del UEC traslada la responsabilidad de la retransmisión de paquetes perdidos de la capa de transporte a la capa de enlace. Esta Repetición a Nivel de Enlace (LLR) permite una recuperación de errores mucho más rápida, ya que los errores se pueden detectar y corregir en un solo salto de red en lugar de tener que esperar un tiempo de ida y vuelta de extremo a extremo.
- Capa Semántica: La pila UET incluye una capa semántica que proporciona una interfaz rica, similar a RDMA, para las aplicaciones. Define códigos de operación (opcodes) para operaciones de SEND, WRITE, READ y ATOMICS, lo que permite una comunicación de memoria a memoria de baja sobrecarga.
La formación del UEC es la formalización de una alianza estratégica. Al estandarizar la pila de comunicaciones completa, el consorcio garantiza que un conmutador de Arista, una NIC de Intel y una DPU de AMD puedan interoperar sin problemas en un fabric de IA de alto rendimiento. Es el mecanismo por el cual el ecosistema fragmentado de Ethernet puede construir colectivamente una solución que sea técnicamente competitiva y económicamente superior a la pila de un solo proveedor de InfiniBand.
La Próxima Frontera: 102.4 Tbps y Más Allá
La industria de la conmutación de redes sigue una cadencia implacable, duplicando el ancho de banda de los ASICs de conmutación cada 18-24 meses. Con los conmutadores de 51.2 Tbps ya en el mercado, la industria mira hacia el próximo hito importante: 102.4 Tbps.
Broadcom Tomahawk 6
Broadcom ya ha anunciado su hoja de ruta para la próxima generación con el Tomahawk 6. Este ASIC de 102.4T está preparado para marcar el comienzo de la era del Ethernet de Terabits, soportando hasta 64 puertos de 1.6 TbE. El chip contará con SerDes PAM4 de 200G, lo que permitirá que un solo conmutador se conecte directamente a 512 XPUs, creando topologías de red aún más planas y de menor latencia.
El Ascenso de la Óptica Co-empaquetada (CPO)
A estas velocidades y densidades de puertos sin precedentes, la energía y la integridad de la señal se convierten en desafíos de primer orden. Las ópticas enchufables tradicionales, que se conectan al panel frontal de un conmutador, consumen una cantidad significativa de energía y requieren trazas eléctricas largas y complejas en la placa de circuito impreso, lo que puede degradar la señal. La Óptica Co-empaquetada (CPO) es una tecnología clave que aborda este problema. La CPO integra los transceptores ópticos en el mismo paquete que el silicio del conmutador. Al acortar drásticamente la distancia eléctrica que la señal debe recorrer, la CPO reduce el consumo de energía, disminuye la latencia y mejora la fiabilidad del enlace. Tanto el Tomahawk 5 como el próximo Tomahawk 6 de Broadcom están diseñados para soportar CPO, lo que indica que esta tecnología será fundamental para permitir la próxima generación de fabrics de IA.
Las Realidades Físicas y Económicas de la Escalada de la IA
La carrera por construir redes de IA más rápidas e inteligentes no ocurre en el vacío. Se está desarrollando en el contexto de duras limitaciones físicas y económicas que, en última instancia, darán forma a la trayectoria de la industria.
El Muro de la Energía y la Refrigeración
La conclusión más importante del análisis de la infraestructura de IA es que la energía y la refrigeración ya no son simplemente costos operativos; son los factores limitantes fundamentales para la escalabilidad de la IA. Los clústeres de IA, con sus racks densamente poblados de GPUs que consumen mucha energía e interconexiones de alta velocidad, generan una densidad de calor sin precedentes. Las densidades de potencia de los racks superan los 120 kW, lo que hace que la refrigeración por aire tradicional sea completamente inadecuada y obliga a una transición costosa y compleja a sistemas de refrigeración líquida avanzados, como la refrigeración directa al chip.
A un nivel más macro, la demanda de energía de los centros de datos está aumentando tan rápidamente que está poniendo a prueba la estabilidad de las redes eléctricas locales y nacionales. En muchas regiones, la falta de energía disponible se ha convertido en el principal obstáculo para la construcción de nuevos centros de datos, lo que provoca retrasos de varios años. Esto significa que la capacidad de escalar un clúster de IA ahora está más limitada por la disponibilidad de megavatios y la capacidad de refrigeración que por la disponibilidad de silicio de red. En consecuencia, la eficiencia energética de los componentes de la red se ha convertido en una restricción de diseño de primer orden. Innovaciones como la CPO y el silicio de bajo consumo ya no son características «agradables de tener»; son necesidades estratégicas. La métrica de «rendimiento por vatio» está eclipsando al «rendimiento» bruto como la variable más crítica en la ecuación de la infraestructura de IA.
La Economía de la Infraestructura
La enorme inversión de capital necesaria para la infraestructura de IA está remodelando la economía digital. La capacidad de construir y operar estos «Fabrics de IA» de manera eficiente se está convirtiendo en una ventaja competitiva clave para las empresas y en una ventaja geopolítica para las naciones.
El futuro de las redes de IA estará definido por tres tendencias convergentes:
- El Triunfo de la Ethernet Abierta: Impulsada por una economía superior y una amplia coalición industrial (el UEC), Ethernet está a punto de convertirse en el fabric dominante para todas las cargas de trabajo de IA, excepto las más especializadas. La apertura, la interoperabilidad y un ecosistema competitivo prevalecerán sobre los jardines amurallados propietarios.
- El Fabric Inteligente: La red seguirá evolucionando desde una simple capa de transporte a un fabric computacional y programable. La computación en red, donde los conmutadores y las DPUs participan activamente en la aceleración de las cargas de trabajo de IA, se convertirá en la norma, desdibujando aún más las líneas entre la computación y la red.
- La Primacía de la Eficiencia: A medida que la industria se acerca a los límites físicos de la energía, la refrigeración y el costo, las soluciones más exitosas serán aquellas que ofrezcan el mayor rendimiento con la mayor eficiencia: en vatios por gigabit, en costo por puerto y en simplicidad operativa. La carrera ya no se trata solo de la velocidad; se trata de una inteligencia sostenible, escalable y económicamente viable.